介紹
介紹 DCGAN 與 Mnist dataset
Mnist 介紹
DCGAN 介紹
請參閱至本篇論文按此點選
DCGAN(Deep Convolutional Generative Adversarial Network),與一般GAN最主要差別是加入捲積引入生成器和鑑別器網絡。
CNN 卷積的概念。通過強制一層的神經元共享權重,前向傳遞(通過網絡提供數據)相當於在圖像上卷積一個濾波器以產生新圖像。然後 CNN 的訓練變成了學習過濾器的任務(決定你應該在數據中尋找哪些特徵。)
特點:
- 取消所有 pooling 層。G 網路中使用轉置卷積(transposed convolutional layer)進行向上取樣,D 網路中用加入 stride 的卷積代替 pooling。
- 在 D 和 G 中均使用 batch normalization
- 去掉 FC 層(全連接層) ,使網路變為 全卷積網路 (Conv2D、Conv2DTranspose)
- G 網路中使用 ReLU 作為啟用函式,最後一層使用 tanh
- D 網路中使用 LeakyReLU 作為啟用函式
ReLU 是所有正值的線性(身份),所有負值為零。Leaky ReLU 對負值的斜率很小,而不是將值推到零。例如,當 x < 0 時,leaky ReLU 可能有 y = 0.01x。
生成器在生成逼真圖像方面逐漸變強,而判別器在辨別這些圖像的能力上逐漸變強。當判別器不再能夠區分真實圖片和偽造圖片時,訓練過程達到平衡。
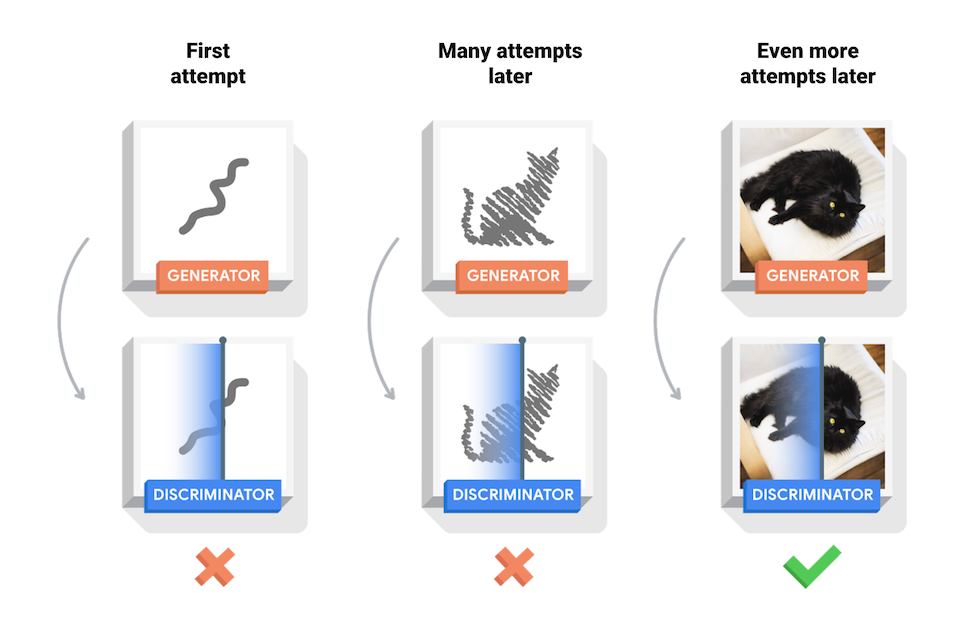
上方圖片來源 tensorglow 範例圖。

上方 GAN 模型結構事意圖。
Import libraries
Preprocessing && load_data
Create model
The Generator
1 | def make_generator_model(): |

上方 generator 模型結構圖。
Test generator
The discriminator
1 | def make_discriminator_model(): |

上方 discriminator 模型結構圖。
Test discriminator
Define the loss and optimizers
loss func
判別器和生成器優化器不同。
1 | #learning rate |
Ex

Save checkpoints
Define the training
training
save img
Train the model && checkpoint
Create a GIF
1 | # Display a single image using the epoch number |
EX:

Save model && load model
1 | def save_model(): |
EX:
